08.indexer
什么是 informers
Kubernetes 控制器的重要作用是监视对象的期望状态和实际状态,然后发送指令以使系统实际状态与期望状态保持一致,这就需要控制器去频繁的实时获取系统中的信息,但是控制器如何获取对象的信息呢? 我们知道 Apiserver 能够提供集群的实时信息。但是,为获取有关资源的信息而进行的连续轮询可能会降低 Apiserver 的性能。为了随时了解这些事件何时被触发,client-go 提供了解决此问题的informer。informer查询资源数据并将其存储在本地缓存中。存储后,仅当检测到对象(或资源)状态的更改时,才会生成事件。
如果您对如何缓存信息感到困惑,这里有一个图表来解释该流程。
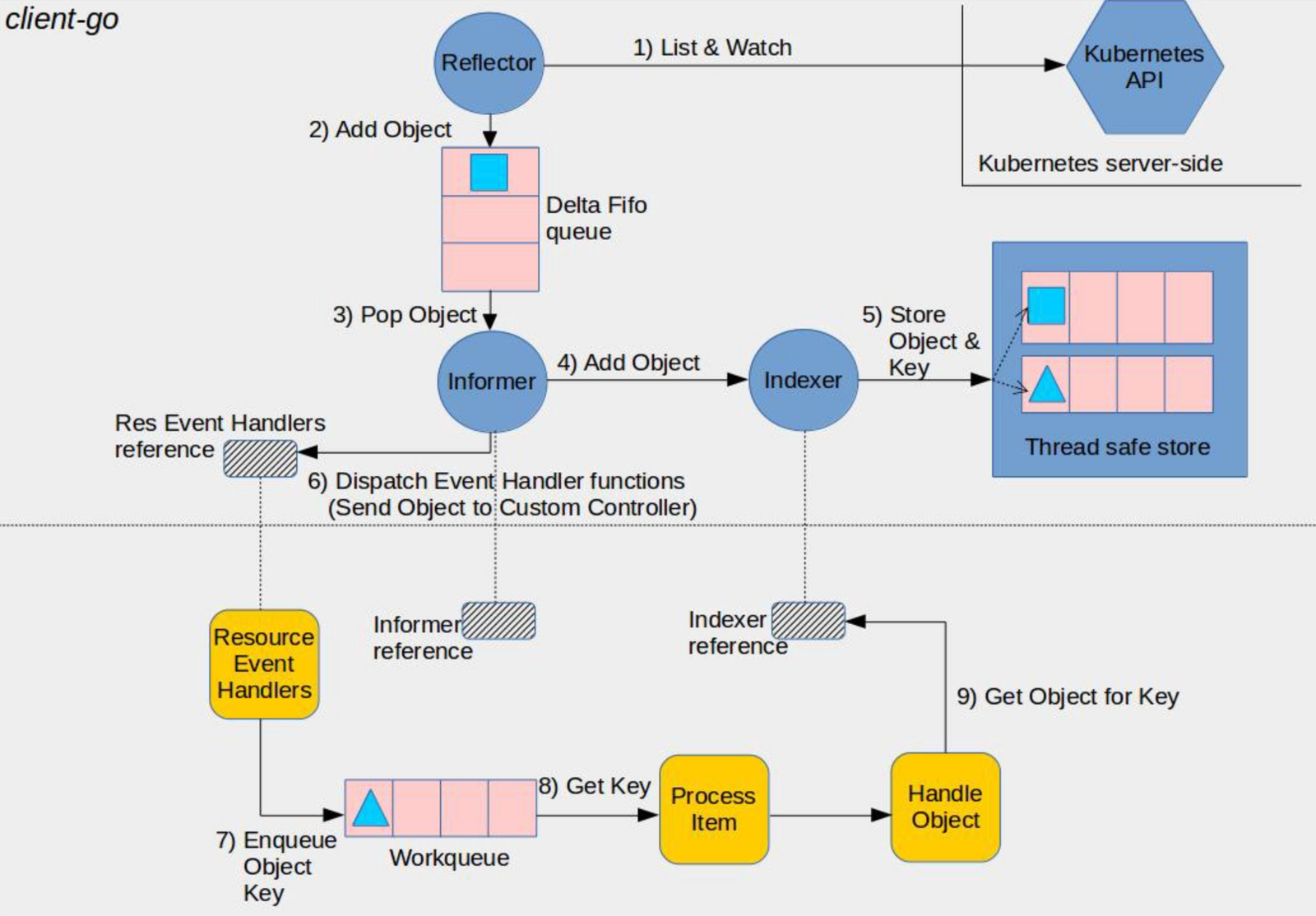
单个informer为自己创建一个本地缓存。但实际上,单个资源可以由多个控制器监视。如果每个控制器为自己创建一个缓存,则存在同步问题,因为多个控制器在自己的缓存上有一个监视。 client-go 提供了一个共享告密者,用于在所有控制器之间共享缓存。每个内置的 Kubernetes 资源都有一个 Informer。
informer 机制有三个部分:
- Reflector :监视特定资源(如某些 CRD),并将 Added 、 Updated 和 Deleted 等事件放入本地缓存 DeltaFIFO 中
- DeltaFIFO : 用于存储相关资源事件的 FIFO 队列
- Indexer : 它是 client-go 实现的本地存储,与 etcd 保持一致,减轻了 API 服务器和 etcd 的压力。
Indexer
Indexer 是 Informer 中一部分,本节我们重点讨论 Indexer 这个组件原理以及源码。Indexer 和数据库类似索引类似,索引构建在存储之上,用来加速查询。 就本质上来说,Index 就是资源对象作为某一个维度的索引值和相关对象 id 集合的对应关系 下面我们来看下什么是 Indexer:
// Indexer extends Store with multiple indices and restricts each
// accumulator to simply hold the current object (and be empty after
// Delete).
//
// There are three kinds of strings here:
// 1. a storage key, as defined in the Store interface,
// 2. a name of an index, and
// 3. an "indexed value", which is produced by an IndexFunc and
// can be a field value or any other string computed from the object.
type Indexer interface {
Store
// Index returns the stored objects whose set of indexed values
// intersects the set of indexed values of the given object, for
// the named index
Index(indexName string, obj interface{}) ([]interface{}, error)
// IndexKeys returns the storage keys of the stored objects whose
// set of indexed values for the named index includes the given
// indexed value
IndexKeys(indexName, indexedValue string) ([]string, error)
// ListIndexFuncValues returns all the indexed values of the given index
ListIndexFuncValues(indexName string) []string
// ByIndex returns the stored objects whose set of indexed values
// for the named index includes the given indexed value
ByIndex(indexName, indexedValue string) ([]interface{}, error)
// GetIndexers return the indexers
GetIndexers() Indexers
// AddIndexers adds more indexers to this store. If you call this after you already have data
// in the store, the results are undefined.
AddIndexers(newIndexers Indexers) error
}
我们看到 Indexer 其实是一个接口的名字,该接口组合了 Store 接口(负责存储数据)。在client-go中实现 Indexer 接口的结构体叫 cache ,我们来看下 cache 结构体的定义:
// `*cache` implements Indexer in terms of a ThreadSafeStore and an
// associated KeyFunc.
type cache struct {
// cacheStorage bears the burden of thread safety for the cache
cacheStorage ThreadSafeStore
// keyFunc is used to make the key for objects stored in and retrieved from items, and
// should be deterministic.
keyFunc KeyFunc
}
// NewIndexer returns an Indexer implemented simply with a map and a lock.
func NewIndexer(keyFunc KeyFunc, indexers Indexers) Indexer {
return &cache{
cacheStorage: NewThreadSafeStore(indexers, Indices{}),
keyFunc: keyFunc,
}
}
// Add inserts an item into the cache.
func (c *cache) Add(obj interface{}) error {
key, err := c.keyFunc(obj)
if err != nil {
return KeyError{obj, err}
}
c.cacheStorage.Add(key, obj)
return nil
}
当我们调用 Indexer 接口的Add方法时,我们首先调用 KeyFunc 来获取对象的 Key(通常是namespace/name) ,然后会调用 c.cacheStorage.Add(key, obj) 方法,该方法底层会先把对象存储到内存,然后重建索引,我们主要着重看下重建索引的部分,这也是网上大部分文章在分析的重点,:
// storeIndex implements the indexing functionality for Store interface
type storeIndex struct {
// indexers maps a name to an IndexFunc
indexers Indexers
// indices maps a name to an Index
indices Indices
}
// Index maps the indexed value to a set of keys in the store that match on that value
type Index map[string]sets.String
// Indexers maps a name to an IndexFunc
type Indexers map[string]IndexFunc
type IndexFunc func(obj interface{}) ([]string, error)
// Indices maps a name to an Index
type Indices map[string]Index
func (i *storeIndex) updateIndices(oldObj interface{}, newObj interface{}, key string) {
var oldIndexValues, indexValues []string
var err error
for name, indexFunc := range i.indexers {
if oldObj != nil {
oldIndexValues, err = indexFunc(oldObj)
} else {
oldIndexValues = oldIndexValues[:0]
}
if err != nil {
panic(fmt.Errorf("unable to calculate an index entry for key %q on index %q: %v", key, name, err))
}
if newObj != nil {
indexValues, err = indexFunc(newObj)
} else {
indexValues = indexValues[:0]
}
if err != nil {
panic(fmt.Errorf("unable to calculate an index entry for key %q on index %q: %v", key, name, err))
}
index := i.indices[name]
if index == nil {
index = Index{}
i.indices[name] = index
}
if len(indexValues) == 1 && len(oldIndexValues) == 1 && indexValues[0] == oldIndexValues[0] {
// We optimize for the most common case where indexFunc returns a single value which has not been changed
continue
}
for _, value := range oldIndexValues {
i.deleteKeyFromIndex(key, value, index)
}
for _, value := range indexValues {
i.addKeyToIndex(key, value, index)
}
}
上面代码中比较重要的是storeIndex,这个结构体有两个成员: Indexers 和 Indices 。Indexers 负责存储索引方法映射关系,在执行NewIndexer 构造函数时候会传 Indexers。 Indices 负责存储 索引和对象的映射关系,方便日后查询,我们来看下面一段具体示例:
index := NewIndexer(MetaNamespaceKeyFunc, Indexers{"byUser": testUsersIndexFunc})
pod1 := &v1.Pod{ObjectMeta: metav1.ObjectMeta{Name: "one", Annotations: map[string]string{"users": "ernie,bert"}}}
pod2 := &v1.Pod{ObjectMeta: metav1.ObjectMeta{Name: "two", Annotations: map[string]string{"users": "bert,oscar"}}}
pod3 := &v1.Pod{ObjectMeta: metav1.ObjectMeta{Name: "tre", Annotations: map[string]string{"users": "ernie,elmo"}}}
index.Add(pod1)
index.Add(pod2)
index.Add(pod3)
indexResults, err := index.ByIndex("byUser", "ernie")
fmt.Println(indexResults)
一图胜千言:

结构
Indexers包含了所有索引器(索引分类)及其索引器函数IndexFunc,IndexFunc为计算某个索引键下的所有对象键列表的方法;
Indexers: {
"索引器1": 索引函数1,
"索引器2": 索引函数2,
}
数据示例:
Indexers: {
"namespace": MetaNamespaceIndexFunc,
"nodeName": NodeNameIndexFunc,
}
func MetaNamespaceIndexFunc(obj interface{}) ([]string, error) {
meta, err := meta.Accessor(obj)
if err != nil {
return []string{""}, fmt.Errorf("object has no meta: %v", err)
}
return []string{meta.GetNamespace()}, nil
}
func NodeNameIndexFunc(obj interface{}) ([]string, error) {
pod, ok := obj.(*v1.Pod)
if !ok {
return []string{""}, fmt.Errorf("object is not a pod)
}
return []string{pod.Spec.NodeName}, nil
}
Indices包含了所有索引器(索引分类)及其所有的索引数据Index;而Index则包含了索引键以及索引键下的所有对象键的列表;
Indices: {
"索引器1": {
"索引键1": ["对象键1", "对象键2"],
"索引键2": ["对象键3"],
},
"索引器2": {
"索引键3": ["对象键1"],
"索引键4": ["对象键2", "对象键3"],
}
}
pod1 := &v1.Pod {
ObjectMeta: metav1.ObjectMeta {
Name: "pod-1",
Namespace: "default",
},
Spec: v1.PodSpec{
NodeName: "node1",
}
}
pod2 := &v1.Pod {
ObjectMeta: metav1.ObjectMeta {
Name: "pod-2",
Namespace: "default",
},
Spec: v1.PodSpec{
NodeName: "node2",
}
}
pod3 := &v1.Pod {
ObjectMeta: metav1.ObjectMeta {
Name: "pod-3",
Namespace: "kube-system",
},
Spec: v1.PodSpec{
NodeName: "node2",
}
}
Indices: {
"namespace": {
"default": ["pod-1", "pod-2"],
"kube-system": ["pod-3"],
},
"nodeName": {
"node1": ["pod-1"],
"node2": ["pod-2", "pod-3"],
}
}
函数
一开始提到Indexer interface,除了继承的Store外,其他的几个方法声明均与索引功能相关,下面对几个常用方法进行介绍。
// staging/src/k8s.io/client-go/tools/cache/index.go
type Indexer interface {
Store
Index(indexName string, obj interface{}) ([]interface{}, error)
IndexKeys(indexName, indexedValue string) ([]string, error)
ListIndexFuncValues(indexName string) []string
ByIndex(indexName, indexedValue string) ([]interface{}, error)
GetIndexers() Indexers
AddIndexers(newIndexers Indexers) error
}
下面的方法介绍基于以下数据:
Indexers: {
"namespace": MetaNamespaceIndexFunc,
"nodeName": NodeNameIndexFunc,
}
Indices: {
"namespace": {
"default": ["pod-1", "pod-2"],
"kube-system": ["pod-3"],
},
"nodeName": {
"node1": ["pod-1"],
"node2": ["pod-2", "pod-3"],
}
}
ByIndex(indexName, indexedValue string) ([]interface{}, error)
调用ByIndex方法,传入索引器名称indexName,以及索引键名称indexedValue,方法寻找该索引器下,索引键对应的对象键列表,然后根据对象键列表,到Indexer缓存(即threadSafeMap中的items属性)中获取出相应的对象列表。
// staging/src/k8s.io/client-go/tools/cache/store.go
func (c *cache) ByIndex(indexName, indexKey string) ([]interface{}, error) {
return c.cacheStorage.ByIndex(indexName, indexKey)
}
// staging/src/k8s.io/client-go/tools/cache/thread_safe_store.go
func (c *threadSafeMap) ByIndex(indexName, indexKey string) ([]interface{}, error) {
c.lock.RLock()
defer c.lock.RUnlock()
indexFunc := c.indexers[indexName]
if indexFunc == nil {
return nil, fmt.Errorf("Index with name %s does not exist", indexName)
}
index := c.indices[indexName]
set := index[indexKey]
list := make([]interface{}, 0, set.Len())
for key := range set {
list = append(list, c.items[key])
}
return list, nil
}
使用示例:
pods, err := index.ByIndex("namespace", "default")
if err != nil {
panic(err)
}
for _, pod := range pods {
fmt.Println(pod.(*v1.Pod).Name)
}
fmt.Println("=====")
pods, err := index.ByIndex("nodename", "node1")
if err != nil {
panic(err)
}
for _, pod := range pods {
fmt.Println(pod.(*v1.Pod).Name)
}
输出:
pod-1
pod-2
=====
pod-1
IndexKeys(indexName, indexedValue string) ([]string, error)
IndexKeys方法与ByIndex方法类似,只不过只返回对象键列表,不会根据对象键列表,到Indexer缓存(即threadSafeMap中的items属性)中获取出相应的对象列表。
// staging/src/k8s.io/client-go/tools/cache/store.go
func (c *cache) IndexKeys(indexName, indexKey string) ([]string, error) {
return c.cacheStorage.IndexKeys(indexName, indexKey)
}
// staging/src/k8s.io/client-go/tools/cache/thread_safe_store.go
func (c *threadSafeMap) IndexKeys(indexName, indexKey string) ([]string, error) {
c.lock.RLock()
defer c.lock.RUnlock()
indexFunc := c.indexers[indexName]
if indexFunc == nil {
return nil, fmt.Errorf("Index with name %s does not exist", indexName)
}
index := c.indices[indexName]
set := index[indexKey]
return set.List(), nil
}
AddIndexers(newIndexers Indexers) error
添加更多的索引器函数
总结
ndexer中有informer维护的指定资源对象的相对于etcd数据的一份本地内存缓存,可通过该缓存获取资源对象,以减少对apiserver、对etcd的请求压力。
informer所维护的缓存依赖于threadSafeMap结构体中的items属性,其本质上是一个用map构建的键值对,资源对象都存在items这个map中,key为资源对象的namespace/name组成,value为资源对象本身,这些构成了informer的本地缓存。
Indexer除了维护了一份本地内存缓存外,还有一个很重要的功能,便是索引功能了。索引的目的就是为了快速查找,比如我们需要查找某个node节点上的所有pod、查找某个命名空间下的所有pod等,利用到索引,可以实现快速查找。关于索引功能,则依赖于threadSafeMap结构体中的indexers与indices属性