1.kubebuilder
概念
crd、controller、operator
- crd 是 k8s 为提高可扩展性,让开发者去自定义资源的规范。
- controller 可以去监听 crd 的变化事件来添加自定义业务逻辑。
- operator 就是 crd + controller ,我们常说的 k8s 二次开发指的就是 operator 开发。
总的来说,CRD、Controller 和 Operator 在 Kubernetes 生态系统中是紧密相关的。CRD 提供了扩展 Kubernetes API 的能力,Controller 提供了通用的资源管理机制,而 Operator 则结合这两者,为复杂应用程序提供高级的管理功能。
k8s 二次开发
Kubernetes 是一个开源的容器编排系统,用于自动化应用程序的部署、扩展和管理。因其功能强大和广泛的生态系统支持,许多公司都在使用 Kubernetes 进行应用部署。如果你希望对 Kubernetes 进行二次开发以适应特定的需求,有几种常见的方式可以考虑:
使用 KubeBuilder 或 Operator SDK 开发operator: 这些工具帮助简化开发 CRDs 和自定义控制器的过程。
开发网络插件 (CNI): 如果你需要自定义 Kubernetes 集群的网络行为,可以考虑开发一个 CNI 插件。
开发存储插件 (CSI): 如果你需要支持特定的存储后端或特性,可以通过开发 CSI 插件来扩展 Kubernetes 的存储能力。
开发调度器: 如果默认的 Kubernetes 调度器不符合你的需求,你可以开发自己的调度器来替代或增强默认的调度逻辑。
开发认证和授权插件: 通过开发自定义的认证和授权插件,你可以增强 Kubernetes 集群的安全性。
API 服务扩展 (Aggregated API Servers): 通过开发聚合 API 服务器,你可以将新的 API 添加到 Kubernetes API 服务器,而无需修改核心 API。
其中最普遍的二次开发就是 operator 开发,Operator 开发 SDK 有 2 个选择:
- kubebuilder
- operator sdk
注意:在本质上其实都是在 K8s 控制器运行时上的封装,主要都是脚手架的生成,使用体验相差不大。但是有意思的是,Kubebuilder 的维护方是:kubernetes-sigs,所以更受人关注,本文主要讲解如何使用 kubebuilder 来开发 operator。下面是 kubebuilder 架构图:
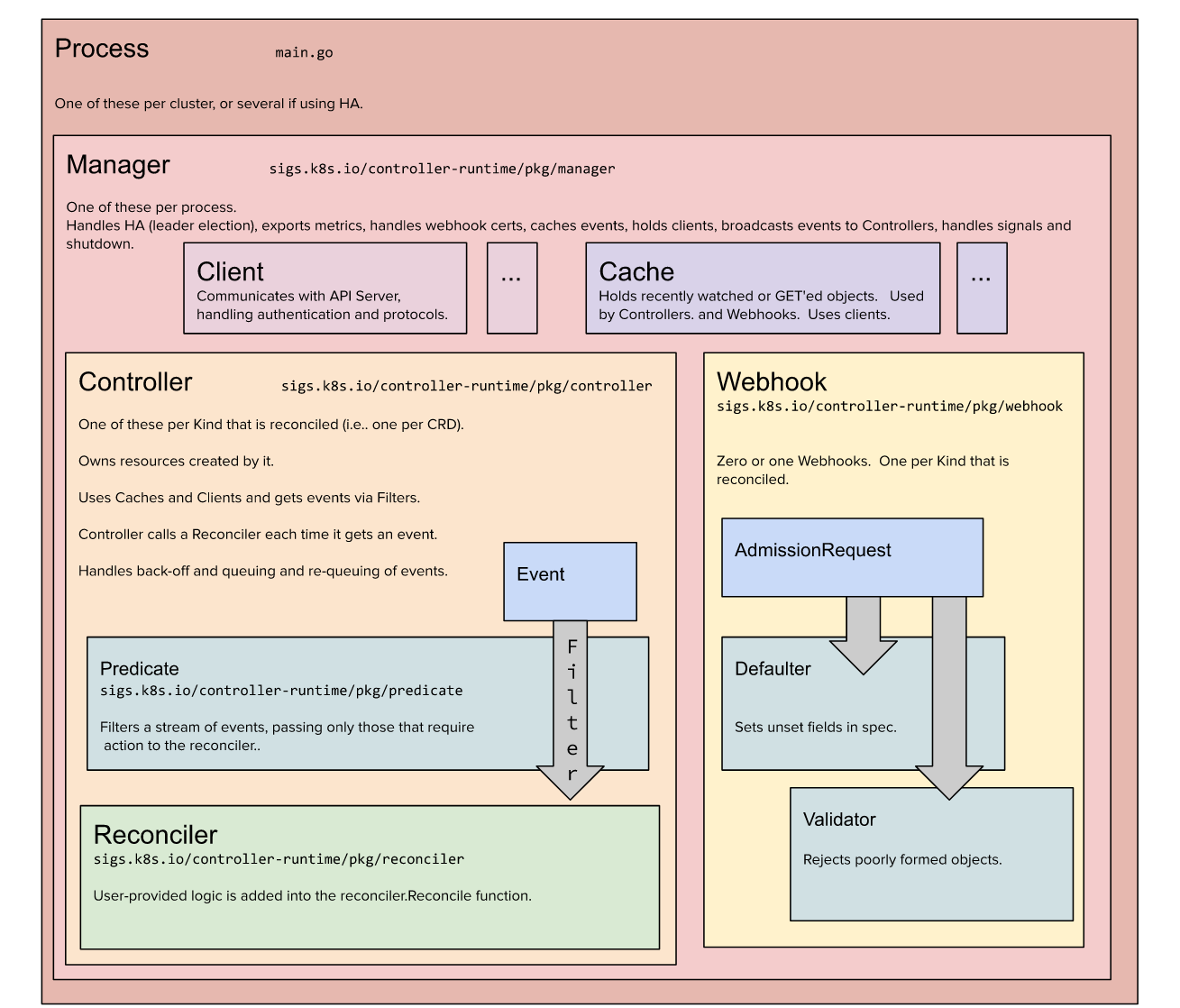
快速开始
安装 kubebuilder
os=$(go env GOOS)
arch=$(go env GOARCH)
# download kubebuilder and extract it to tmp
curl -L https://go.kubebuilder.io/dl/2.3.1/${os}/${arch} | tar -xz -C /tmp/
# move to a long-term location and put it on your path
# (you'll need to set the KUBEBUILDER_ASSETS env var if you put it somewhere else)
sudo mv /tmp/kubebuilder_2.3.1_${os}_${arch} /usr/local/kubebuilder
export PATH=$PATH:/usr/local/kubebuilder/bin
创建项目
mkdir example
cd example
kubebuilder init --domain my.domain
go mod init xxx
go mod tidy
kubebuilder 会帮我们生成一个框架,我们在此框架上进行 k8s 二次开发,下面是框架的目录结构:
❯ tree -L 3
.
├── Dockerfile
├── Makefile
├── PROJECT
├── README.md
├── cmd
│ └── main.go
├── config
│ ├── default
│ │ ├── kustomization.yaml
│ │ ├── manager_auth_proxy_patch.yaml
│ │ └── manager_config_patch.yaml
│ ├── manager
│ │ ├── kustomization.yaml
│ │ └── manager.yaml
│ ├── prometheus
│ │ ├── kustomization.yaml
│ │ └── monitor.yaml
│ └── rbac
│ ├── auth_proxy_client_clusterrole.yaml
│ ├── auth_proxy_role.yaml
│ ├── auth_proxy_role_binding.yaml
│ ├── auth_proxy_service.yaml
│ ├── kustomization.yaml
│ ├── leader_election_role.yaml
│ ├── leader_election_role_binding.yaml
│ ├── role_binding.yaml
│ └── service_account.yaml
├── go.mod
├── go.sum
└── hack
└── boilerplate.go.txt
Dockerfile: 用于构建 Docker 镜像的文件。Makefile: 一个 Makefile,其中包含了用于构建和发布 Operator 的常用命令。PROJECT: 项目名称,以及项目信息,这里是一些 metadata 。README.md: 项目的说明文档。cmd/: 包含了 Operator 的入口程序main.go。config/: 包含了 Operator 的配置文件,包括 RBAC 权限相关的 YAML 文件、Prometheus 监控服务发现(ServiceMonitor)相关的 Yaml 文件、控制器(Manager)部分部署的 Yaml 文件。default/: 包含了默认的配置文件。kustomization.yaml: Kustomize 配置文件,指定了需要应用的 k8s 资源类型和名称。manager_auth_proxy_patch.yaml: 在 manager 容器中添加了 auth-proxy 容器的相关信息。manager_config_patch.yaml: 在 manager 容器中添加了与 Operator 相关的配置信息。
manager/: 包含了部署 Operator 所需的 k8s 资源文件。kustomization.yaml: Kustomize 配置文件,指定了需要应用的 k8s 资源类型和名称。manager.yaml: 部署 Operator 所需的 k8s 资源文件。
prometheus/: 包含了 Prometheus 监控 Operator 所需的 k8s 资源文件。kustomization.yaml: Kustomize 配置文件,指定了需要应用的 k8s 资源类型和名称。monitor.yaml: 部署 Prometheus 监控 Operator 所需的 k8s 资源文件。
rbac/: 包含了 Operator 所需的 RBAC 资源文件。auth_proxy_client_clusterrole.yaml: 配置了与客户端授权相关的 ClusterRole。auth_proxy_role.yaml: 配置了与 auth-proxy 相关的 Role。auth_proxy_role_binding.yaml: 配置了与 auth-proxy 相关的 RoleBinding。auth_proxy_service.yaml: 配置了与 auth-proxy 相关的 Service。kustomization.yaml: Kustomize 配置文件,指定了需要应用的 k8s 资源类型和名称。leader_election_role.yaml: 配置了与 leader election 相关的 Role。leader_election_role_binding.yaml: 配置了与 leader election 相关的 RoleBinding。role_binding.yaml: 配置了与 Operator 相关的 RoleBinding。service_account.yaml: 配置了与 Operator 相关的 ServiceAccount。
go.mod: Go 项目的模块文件。go.sum: Go 项目的模块依赖文件。hack/: 包含了生成代码和文档等相关的脚本和文件。boilerplate.go.txt: 用于生成 Go 项目文件的代码模板。
创建 API
Kubernetes 的资源本质就是一个 API 对象,不过这个对象的 期望状态 被 API Service 保存在了 ETCD 中(或者是对于 k3s 来说可以保存在其他的有状态数据库,包括 sqlite、dqlite、mysql…,然后提供 RESTful 接口用于 更新这些对象。
运行以下命令,创建一个新的 API(组/版本)作为 webapp/v1 ,并在其上创建新的 Kind(CRD) Guestbook 。创建时会弹出提示问我们是否要生成 controller 代码,一般选择 yes。
kubebuilder create api --group webapp --version v1 --kind Guestbook
新增目录:
api:包含刚刚添加的 API,后面会经常编辑这里的guestbook_types.go文件。这个文件是 CRD 代码的主要定义文件。config/crd:存放的是 crd 部署相关的 kustomize 文件。config/rbac/:分别是编辑权限和查询权限的ClusterRolesamples:很好理解,CR 示例文件internal:很好理解,内部核心代码,我们打开看看controllers
我们在上面讲过,CRD 的代码定义主要在 api/ 目录下面,我们看一下代码结构:
❯ tree api
api
└── v1
├── groupversion_info.go
├── guestbook_types.go
└── zz_generated.deepcopy.go
guestbook_types.go 文件主要的定义,我们看下 spec 结构。
在Go语言中,结构体以 spec 结尾表示该结构体是用于特定目的的规范结构体。这种命名约定通常用于描述一个结构体的用途和功能,以便开发人员更好地理解和使用它。例如,GuestbookSpec定义了所需的 Guestbook 状态
// GuestbookSpec defines the desired state of Guestbook
type GuestbookSpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "make" to regenerate code after modifying this file
// Foo is an example field of Guestbook. Edit guestbook_types.go to remove/update
Foo string `json:"foo,omitempty"`
}
上面的注释写的很清楚,Foo 是一个示例,我们可以删除掉,然后添加自己需要的字段。修改这个文件后利用 Makefile 指令重新生成代码,简单的一个案例如下💡:
import (
corev1 "k8s.io/api/core/v1"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
type GuestbookSpec struct {
Replicas int32 `json:"replicas,omitempty"`
Template corev1.PodTemplateSpec `json:"template,omitempty"`
}
在集群运行
由于我们是基于k8s做二次开发,要求在 .kube 目录下有可用集群的 kubeconfig 配置文件。
- 将 CRD 安装到集群中:
make install
- 本地运行您的控制器
make run
卸载 crds
make uninstall
写一个 cronJob
让我们假装厌倦了 Kubernetes 中 CronJob 控制器的非 Kubebuilder 实现的维护负担,我们想使用 KubeBuilder 重写它。
CronJob 控制器的定期在 Kubernetes 集群上运行一次性任务。它通过在job控制器之上构建来实现这一点,job控制器的任务是运行一次性任务一次,看到它们完成。
搭建项目
如快速开始中所述,我们需要搭建一个新项目的脚手架。确保你已经安装了 Kubebuilder,然后执行以下步骤:
# we'll use a domain of tutorial.kubebuilder.io,
# so all API groups will be <group>.tutorial.kubebuilder.io.
kubebuilder init --domain tutorial.kubebuilder.io
我们先来看下启动配置目录 config/ ,现在它只包含群集上启动控制器所需的 Kustomize YAML 定义,但是一旦我们开始编写控制器,它还将包含我们的 crd 资源定义、RBAC 配置和 Webhook配置。
Kubebuilder 搭建了我们项目的基本入口点: main.go 。 接下来让我们来看看 main.go
main.go
每组控制器都需要一个 scheme ,该方案提供种类与其相应的 Go 类型之间的映射。当我们编写 API 定义时,我们将更多地讨论种类,所以请记住这一点,以便稍后使用。
var (
scheme = runtime.NewScheme()
setupLog = ctrl.Log.WithName("setup")
)
func init() {
// +kubebuilder:scaffold:scheme
}
func main() {
var metricsAddr string
flag.StringVar(&metricsAddr, "metrics-addr", ":8080", "The address the metric endpoint binds to.")
flag.Parse()
ctrl.SetLogger(zap.New(zap.UseDevMode(true)))
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{Scheme: scheme, MetricsBindAddress: metricsAddr})
if err != nil {
setupLog.Error(err, "unable to start manager")
os.Exit(1)
}
- 我们为 metrics 设置了一些基本 flags。
- 我们实例化一个 manager ,它跟踪运行我们所有的控制器,以及设置 API 服务器的共享缓存和客户端(请注意,我们告诉manager 我们的 scheme)
- 我们运行我们的 manager ,它反过来运行我们所有的控制器和 webhook。管理器设置为运行,直到收到正常关闭信号。这样,当我们在 Kubernetes 上运行时,我们在优雅的 pod 终止方面表现得很好。
请注意,manager 可以通过以下方式限制所有控制器将监视资源的命名空间:
mgr, err = ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
Namespace: namespace,
MetricsBindAddress: metricsAddr,
})
上面的示例会将项目的范围更改为单个命名空间。在此方案中,还建议通过将默认的 ClusterRole 和 ClusterRoleBinding 分别替换为 Role 和 RoleBinding 来限制对此命名空间提供的授权 有关详细信息,请参阅有关使用 RBAC 授权的 kubernetes 文档。
此外,还可以使用 MultiNamespacedCacheBuilder 来监视一组特定的命名空间:
var namespaces []string // List of Namespaces
mgr, err = ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
NewCache: cache.MultiNamespacedCacheBuilder(namespaces),
MetricsBindAddress: fmt.Sprintf("%s:%d", metricsHost, metricsPort),
})
// +kubebuilder:scaffold:builder
setupLog.Info("starting manager")
if err := mgr.Start(ctrl.SetupSignalHandler()); err != nil {
setupLog.Error(err, "problem running manager")
os.Exit(1)
}
}
添加一个新的 api
kubebuilder create api --group batch --version v1 --kind CronJob
我们第一次为每个组版本调用此命令时,它将为新的组版本创建一个目录。在这种情况下,创建 api/v1/ 目录,对应于 batch.tutorial.kubebuilder.io/v1 (还记得我们从一开始就设置的 --domain 吗?
它还为我们的 CronJob Kind生成一个 api/v1/cronjob_types.go 文件。每次我们调用 kubebuilder create api命令时,它都会生成一个对应资源的新文件。
package v1
import (
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
/*
Next, we define types for the Spec and Status of our Kind. Kubernetes functions
by reconciling desired state (`Spec`) with actual cluster state (other objects'
`Status`) and external state, and then recording what it observed (`Status`).
Thus, every *functional* object includes spec and status. A few types, like
`ConfigMap` don't follow this pattern, since they don't encode desired state,
but most types do.
*/
// EDIT THIS FILE! THIS IS SCAFFOLDING FOR YOU TO OWN!
// NOTE: json tags are required. Any new fields you add must have json tags for the fields to be serialized.
// CronJobSpec defines the desired state of CronJob
type CronJobSpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "make" to regenerate code after modifying this file
}
// CronJobStatus defines the observed state of CronJob
type CronJobStatus struct {
// INSERT ADDITIONAL STATUS FIELD - define observed state of cluster
// Important: Run "make" to regenerate code after modifying this file
}
/*
Next, we define the types corresponding to actual Kinds, `CronJob` and `CronJobList`.
`CronJob` is our root type, and describes the `CronJob` kind. Like all Kubernetes objects, it contains
`TypeMeta` (which describes API version and Kind), and also contains `ObjectMeta`, which holds things
like name, namespace, and labels.
`CronJobList` is simply a container for multiple `CronJob`s. It's the Kind used in bulk operations,
like LIST.
In general, we never modify either of these -- all modifications go in either Spec or Status.
That little `+kubebuilder:object:root` comment is called a marker. We'll see
more of them in a bit, but know that they act as extra metadata, telling
[controller-tools](https://github.com/kubernetes-sigs/controller-tools) (our code and YAML generator) extra information.
This particular one tells the `object` generator that this type represents
a Kind. Then, the `object` generator generates an implementation of the
[runtime.Object](https://pkg.go.dev/k8s.io/apimachinery/pkg/runtime?tab=doc#Object) interface for us, which is the standard
interface that all types representing Kinds must implement.
*/
//+kubebuilder:object:root=true
//+kubebuilder:subresource:status
// CronJob is the Schema for the cronjobs API
type CronJob struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec CronJobSpec `json:"spec,omitempty"`
Status CronJobStatus `json:"status,omitempty"`
}
//+kubebuilder:object:root=true
// CronJobList contains a list of CronJob
type CronJobList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []CronJob `json:"items"`
}
/*
Finally, we add the Go types to the API group. This allows us to add the
types in this API group to any [Scheme](https://pkg.go.dev/k8s.io/apimachinery/pkg/runtime?tab=doc#Scheme).
*/
func init() {
SchemeBuilder.Register(&CronJob{}, &CronJobList{})
}
Kubernetes 通过将期望状态(Spec) 与实际集群状态(其他对象的 Status)和外部状态进行协调,然后记录它观察到的内容 ( Status ) 来发挥作用。因此,每个功能对象都包括规范和状态。一些类型(如 ConfigMap )不遵循此模式,因为它们不对所需状态进行编码,但大多数类型都这样做。
// EDIT THIS FILE! THIS IS SCAFFOLDING FOR YOU TO OWN!
// NOTE: json tags are required. Any new fields you add must have json tags for the fields to be serialized.
// CronJobSpec defines the desired state of CronJob
type CronJobSpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "make" to regenerate code after modifying this file
}
// CronJobStatus defines the observed state of CronJob
type CronJobStatus struct {
// INSERT ADDITIONAL STATUS FIELD - define observed state of cluster
// Important: Run "make" to regenerate code after modifying this file
}
接下来,我们定义 CronJob 和 CronJobList 对应的类型。 CronJob 是我们的根类型,描述了 CronJob 种。像所有 Kubernetes 对象一样,它包含 TypeMeta (描述 API 版本和种类),还包含 ObjectMeta 个,其中包含名称、命名空间和标签等内容。CronJobList 只是多个 CronJob 的容器.
// +kubebuilder:object:root=true
// CronJob is the Schema for the cronjobs API
type CronJob struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec CronJobSpec `json:"spec,omitempty"`
Status CronJobStatus `json:"status,omitempty"`
}
// +kubebuilder:object:root=true
// CronJobList contains a list of CronJob
type CronJobList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []CronJob `json:"items"`
}
最后,我们将 Go 类型添加到 API 组。这允许我们将此 API 组中的类型添加到任何 scheme 中。
func init() {
SchemeBuilder.Register(&CronJob{}, &CronJobList{})
}
定义 api
在 Kubernetes 中,我们对如何设计 API 有一些规则。也就是说,所有序列化字段都必须为 camelCase ,因此我们使用 JSON 结构标签来指定这一点。我们还可以使用 omitempty struct 标签来标记字段在为空时应从序列化中省略。让我们来看看我们的 CronJob 对象是什么样的!
/*
Copyright 2023 The Kubernetes authors.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
// +kubebuilder:docs-gen:collapse=Apache License
/*
*/
package v1
/*
*/
import (
batchv1 "k8s.io/api/batch/v1"
corev1 "k8s.io/api/core/v1"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
)
// EDIT THIS FILE! THIS IS SCAFFOLDING FOR YOU TO OWN!
// NOTE: json tags are required. Any new fields you add must have json tags for the fields to be serialized.
// +kubebuilder:docs-gen:collapse=Imports
/*
First, let's take a look at our spec. As we discussed before, spec holds
*desired state*, so any "inputs" to our controller go here.
Fundamentally a CronJob needs the following pieces:
- A schedule (the *cron* in CronJob)
- A template for the Job to run (the
*job* in CronJob)
We'll also want a few extras, which will make our users' lives easier:
- A deadline for starting jobs (if we miss this deadline, we'll just wait till
the next scheduled time)
- What to do if multiple jobs would run at once (do we wait? stop the old one? run both?)
- A way to pause the running of a CronJob, in case something's wrong with it
- Limits on old job history
Remember, since we never read our own status, we need to have some other way to
keep track of whether a job has run. We can use at least one old job to do
this.
We'll use several markers (`// +comment`) to specify additional metadata. These
will be used by [controller-tools](https://github.com/kubernetes-sigs/controller-tools) when generating our CRD manifest.
As we'll see in a bit, controller-tools will also use GoDoc to form descriptions for
the fields.
*/
// CronJobSpec defines the desired state of CronJob
type CronJobSpec struct {
//+kubebuilder:validation:MinLength=0
// The schedule in Cron format, see https://en.wikipedia.org/wiki/Cron.
Schedule string `json:"schedule"`
//+kubebuilder:validation:Minimum=0
// Optional deadline in seconds for starting the job if it misses scheduled
// time for any reason. Missed jobs executions will be counted as failed ones.
// +optional
StartingDeadlineSeconds *int64 `json:"startingDeadlineSeconds,omitempty"`
// Specifies how to treat concurrent executions of a Job.
// Valid values are:
// - "Allow" (default): allows CronJobs to run concurrently;
// - "Forbid": forbids concurrent runs, skipping next run if previous run hasn't finished yet;
// - "Replace": cancels currently running job and replaces it with a new one
// +optional
ConcurrencyPolicy ConcurrencyPolicy `json:"concurrencyPolicy,omitempty"`
// This flag tells the controller to suspend subsequent executions, it does
// not apply to already started executions. Defaults to false.
// +optional
Suspend *bool `json:"suspend,omitempty"`
// Specifies the job that will be created when executing a CronJob.
JobTemplate batchv1.JobTemplateSpec `json:"jobTemplate"`
//+kubebuilder:validation:Minimum=0
// The number of successful finished jobs to retain.
// This is a pointer to distinguish between explicit zero and not specified.
// +optional
SuccessfulJobsHistoryLimit *int32 `json:"successfulJobsHistoryLimit,omitempty"`
//+kubebuilder:validation:Minimum=0
// The number of failed finished jobs to retain.
// This is a pointer to distinguish between explicit zero and not specified.
// +optional
FailedJobsHistoryLimit *int32 `json:"failedJobsHistoryLimit,omitempty"`
}
/*
We define a custom type to hold our concurrency policy. It's actually
just a string under the hood, but the type gives extra documentation,
and allows us to attach validation on the type instead of the field,
making the validation more easily reusable.
*/
// ConcurrencyPolicy describes how the job will be handled.
// Only one of the following concurrent policies may be specified.
// If none of the following policies is specified, the default one
// is AllowConcurrent.
// +kubebuilder:validation:Enum=Allow;Forbid;Replace
type ConcurrencyPolicy string
const (
// AllowConcurrent allows CronJobs to run concurrently.
AllowConcurrent ConcurrencyPolicy = "Allow"
// ForbidConcurrent forbids concurrent runs, skipping next run if previous
// hasn't finished yet.
ForbidConcurrent ConcurrencyPolicy = "Forbid"
// ReplaceConcurrent cancels currently running job and replaces it with a new one.
ReplaceConcurrent ConcurrencyPolicy = "Replace"
)
/*
Next, let's design our status, which holds observed state. It contains any information
we want users or other controllers to be able to easily obtain.
We'll keep a list of actively running jobs, as well as the last time that we successfully
ran our job. Notice that we use `metav1.Time` instead of `time.Time` to get the stable
serialization, as mentioned above.
*/
// CronJobStatus defines the observed state of CronJob
type CronJobStatus struct {
// INSERT ADDITIONAL STATUS FIELD - define observed state of cluster
// Important: Run "make" to regenerate code after modifying this file
// A list of pointers to currently running jobs.
// +optional
Active []corev1.ObjectReference `json:"active,omitempty"`
// Information when was the last time the job was successfully scheduled.
// +optional
LastScheduleTime *metav1.Time `json:"lastScheduleTime,omitempty"`
}
/*
Finally, we have the rest of the boilerplate that we've already discussed.
As previously noted, we don't need to change this, except to mark that
we want a status subresource, so that we behave like built-in kubernetes types.
*/
//+kubebuilder:object:root=true
//+kubebuilder:subresource:status
// CronJob is the Schema for the cronjobs API
type CronJob struct {
/*
*/
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec CronJobSpec `json:"spec,omitempty"`
Status CronJobStatus `json:"status,omitempty"`
}
//+kubebuilder:object:root=true
// CronJobList contains a list of CronJob
type CronJobList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []CronJob `json:"items"`
}
func init() {
SchemeBuilder.Register(&CronJob{}, &CronJobList{})
}
//+kubebuilder:docs-gen:collapse=Root Object Definitions
首先,让我们看一下我们的 spec 。正如我们之前所讨论的,spec 保存预期状态,因此控制器的任何“输入”都在这里。
从根本上说,CronJob 需要以下部分:
- 一个 schedule(CronJob中的cron)
- 要运行 job 的模板(CronJob 中的job)
我们还需要一些额外的功能:
- 开始工作的截止日期(如果我们错过了这个截止日期,我们将等到下一个预定时间)
- 如果多个job同时运行怎么办(我们等待吗?停止旧的?同时运行两个?)
- 一种暂停CronJob运行的方法,以防出现问题
- 对旧job历史记录的限制
请记住,由于我们从不读取自己的状态,因此我们需要其他方法来跟踪job是否已运行。我们至少可以使用一个旧 job 来做到这一点。
我们定义一个自定义类型来保存我们的并发策略。它实际上只是一个底层的字符串,但类型提供了额外的文档,并允许我们在类型而不是字段上附加验证,使验证更容易重用。
// ConcurrencyPolicy describes how the job will be handled.
// Only one of the following concurrent policies may be specified.
// If none of the following policies is specified, the default one
// is AllowConcurrent.
// +kubebuilder:validation:Enum=Allow;Forbid;Replace
type ConcurrencyPolicy string
const (
// AllowConcurrent allows CronJobs to run concurrently.
AllowConcurrent ConcurrencyPolicy = "Allow"
// ForbidConcurrent forbids concurrent runs, skipping next run if previous
// hasn't finished yet.
ForbidConcurrent ConcurrencyPolicy = "Forbid"
// ReplaceConcurrent cancels currently running job and replaces it with a new one.
ReplaceConcurrent ConcurrencyPolicy = "Replace"
)
接下来,让我们设计我们的状态,它包含观察状态。它包含我们希望用户或其他控制者能够轻松获取的任何信息。
我们将保留活动正在运行的 jobs 的列表,以及上次成功运行 job 的时间。
// CronJobStatus defines the observed state of CronJob
type CronJobStatus struct {
// INSERT ADDITIONAL STATUS FIELD - define observed state of cluster
// Important: Run "make" to regenerate code after modifying this file
// A list of pointers to currently running jobs.
// +optional
Active []corev1.ObjectReference `json:"active,omitempty"`
// Information when was the last time the job was successfully scheduled.
// +optional
LastScheduleTime *metav1.Time `json:"lastScheduleTime,omitempty"`
}
现在我们有了一个 API,我们需要编写一个控制器来实际实现该功能。
控制器
控制器是 Kubernetes 和任何 operator 的核心。
控制器的工作是确保对于任何给定对象,世界的实际状态(集群状态和潜在的外部状态,如为 Kubelet 运行容器或为云提供商运行负载均衡器)与对象中的所需状态匹配。每个控制器专注于一种根种类,但可以与其他种类交互。
我们称此过程为 reconciling(协调)。
在控制器运行时中,实现特定类型的协调的逻辑称为协调器。协调器获取对象的名称,并返回我们是否需要重试(例如,在出现错误或周期性控制器的情况下,如 HorizontalPodAutoscaler)。
/*
Copyright 2022.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
// +kubebuilder:docs-gen:collapse=Apache License
/*
First, we start out with some standard imports.
As before, we need the core controller-runtime library, as well as
the client package, and the package for our API types.
*/
package controllers
import (
"context"
"k8s.io/apimachinery/pkg/runtime"
ctrl "sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/client"
"sigs.k8s.io/controller-runtime/pkg/log"
batchv1 "tutorial.kubebuilder.io/project/api/v1"
)
/*
Next, kubebuilder has scaffolded a basic reconciler struct for us.
Pretty much every reconciler needs to log, and needs to be able to fetch
objects, so these are added out of the box.
*/
// CronJobReconciler reconciles a CronJob object
type CronJobReconciler struct {
client.Client
Scheme *runtime.Scheme
}
/*
Most controllers eventually end up running on the cluster, so they need RBAC
permissions, which we specify using controller-tools [RBAC
markers](/reference/markers/rbac.md). These are the bare minimum permissions
needed to run. As we add more functionality, we'll need to revisit these.
*/
// +kubebuilder:rbac:groups=batch.tutorial.kubebuilder.io,resources=cronjobs,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=batch.tutorial.kubebuilder.io,resources=cronjobs/status,verbs=get;update;patch
/*
The `ClusterRole` manifest at `config/rbac/role.yaml` is generated from the above markers via controller-gen with the following command:
*/
// make manifests
/*
NOTE: If you receive an error, please run the specified command in the error and re-run `make manifests`.
*/
/*
`Reconcile` actually performs the reconciling for a single named object.
Our [Request](https://pkg.go.dev/sigs.k8s.io/controller-runtime/pkg/reconcile?tab=doc#Request) just has a name, but we can use the client to fetch
that object from the cache.
We return an empty result and no error, which indicates to controller-runtime that
we've successfully reconciled this object and don't need to try again until there's
some changes.
Most controllers need a logging handle and a context, so we set them up here.
The [context](https://golang.org/pkg/context/) is used to allow cancelation of
requests, and potentially things like tracing. It's the first argument to all
client methods. The `Background` context is just a basic context without any
extra data or timing restrictions.
The logging handle lets us log. controller-runtime uses structured logging through a
library called [logr](https://github.com/go-logr/logr). As we'll see shortly,
logging works by attaching key-value pairs to a static message. We can pre-assign
some pairs at the top of our reconcile method to have those attached to all log
lines in this reconciler.
*/
func (r *CronJobReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
_ = log.FromContext(ctx)
// your logic here
return ctrl.Result{}, nil
}
/*
Finally, we add this reconciler to the manager, so that it gets started
when the manager is started.
For now, we just note that this reconciler operates on `CronJob`s. Later,
we'll use this to mark that we care about related objects as well.
*/
func (r *CronJobReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&batchv1.CronJob{}).
Complete(r)
}
接下来,kubebuilder 为我们搭建了一个基本的协调器结构。几乎每个协调器都需要 log ,并且需要能够获取对象,因此这些对象是开箱即用的。
// CronJobReconciler reconciles a CronJob object
type CronJobReconciler struct {
client.Client
Log logr.Logger
Scheme *runtime.Scheme
}
大多数控制器最终会在群集上运行,因此它们需要 RBAC 权限,我们使用控制器工具 RBAC 标记指定这些权限。这些是运行所需的最低权限。
// +kubebuilder:rbac:groups=batch.tutorial.kubebuilder.io,resources=cronjobs,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=batch.tutorial.kubebuilder.io,resources=cronjobs/status,verbs=get;update;patch
Reconcile 实际上对单个命名对象执行协调。我们的请求只有一个名称,但我们可以使用客户端从缓存中获取该对象。
大多数控制器都需要 log 和 context,因此我们在此处设置它们。context 允许我们传递上下文,log 允许我们记录日志。
func (r *CronJobReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
_ = context.Background()
_ = r.Log.WithValues("cronjob", req.NamespacedName)
// your logic here
return ctrl.Result{}, nil
}
最后,我们将此协调器添加到管理器,以便在管理器启动时启动它。
func (r *CronJobReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&batchv1.CronJob{}).
Complete(r)
}
现在我们已经了解了协调器的基本结构,让我们填写 CronJob 的逻辑。
实现控制器
我们的 CronJob 控制器的基本逻辑是这样的:
- 加载命名的 CronJob
- 列出所有活动 jobs,并更新状态
- 根据历史记录限制清理旧job
- 检查我们是否被暂停(如果我们被暂停,请不要执行任何其他操作)
- 获取下一次scheduled run
- 如果新 job 按计划运行、未超过截止时间且未被我们的并发策略阻止,则运行新 job
- 当我们看到正在运行的job(自动完成)或下一次计划运行时重新排队。
我们需要一个时钟,这将允许我们在测试中伪造计时。
// CronJobReconciler reconciles a CronJob object
type CronJobReconciler struct {
client.Client
Log logr.Logger
Scheme *runtime.Scheme
Clock
}
1.按照名字加载 cronjob
我们将使用客户端获取 CronJob。所有客户端方法都将 context(允许取消)作为其第一个参数,并将相关对象作为其最后一个参数。Get 有点特别,因为它需要 NamespacedName 作为参数。
var cronJob batch.CronJob
if err := r.Get(ctx, req.NamespacedName, &cronJob); err != nil {
log.Error(err, "unable to fetch CronJob")
// we'll ignore not-found errors, since they can't be fixed by an immediate
// requeue (we'll need to wait for a new notification), and we can get them
// on deleted requests.
return ctrl.Result{}, client.IgnoreNotFound(err)
}
2.列出所有 active jobs,并且更新 status
若要完全更新状态,我们需要列出此命名空间中属于此 CronJob 的所有子job。与 Get 类似,我们可以使用 List 方法来列出子job。请注意,我们使用可变参数选项来设置命名空间和字段匹配(这实际上是我们在下面设置的索引查找)。
var childJobs kbatch.JobList
if err := r.List(ctx, &childJobs, client.InNamespace(req.Namespace), client.MatchingFields{jobOwnerKey: req.Name}); err != nil {
log.Error(err, "unable to list child Jobs")
return ctrl.Result{}, err
}
拥有我们拥有的所有 jobs 后,我们会将它们拆分为活动、成功和失败的 job,跟踪最近的运行,以便我们可以将其记录在状态中。请记住,状态应该能够从世界状态中重构,因此从根对象的状态读取通常不是一个好主意。相反,您应该在每次运行时重建它。这就是我们在这里要做的。
我们可以使用状态条件检查job是否“完成”以及它是成功还是失败。我们将把这个逻辑放在一个帮助程序中,使我们的代码更干净。
// find the active list of jobs
var activeJobs []*kbatch.Job
var successfulJobs []*kbatch.Job
var failedJobs []*kbatch.Job
var mostRecentTime *time.Time // find the last run so we can update the status
isJobFinished := func(job *kbatch.Job) (bool, kbatch.JobConditionType) {
for _, c := range job.Status.Conditions {
if (c.Type == kbatch.JobComplete || c.Type == kbatch.JobFailed) && c.Status == corev1.ConditionTrue {
return true, c.Type
}
}
return false, ""
}
getScheduledTimeForJob := func(job *kbatch.Job) (*time.Time, error) {
timeRaw := job.Annotations[scheduledTimeAnnotation]
if len(timeRaw) == 0 {
return nil, nil
}
timeParsed, err := time.Parse(time.RFC3339, timeRaw)
if err != nil {
return nil, err
}
return &timeParsed, nil
}
for i, job := range childJobs.Items {
_, finishedType := isJobFinished(&job)
switch finishedType {
case "": // ongoing
activeJobs = append(activeJobs, &childJobs.Items[i])
case kbatch.JobFailed:
failedJobs = append(failedJobs, &childJobs.Items[i])
case kbatch.JobComplete:
successfulJobs = append(successfulJobs, &childJobs.Items[i])
}
// We'll store the launch time in an annotation, so we'll reconstitute that from
// the active jobs themselves.
scheduledTimeForJob, err := getScheduledTimeForJob(&job)
if err != nil {
log.Error(err, "unable to parse schedule time for child job", "job", &job)
continue
}
if scheduledTimeForJob != nil {
if mostRecentTime == nil {
mostRecentTime = scheduledTimeForJob
} else if mostRecentTime.Before(*scheduledTimeForJob) {
mostRecentTime = scheduledTimeForJob
}
}
}
if mostRecentTime != nil {
cronJob.Status.LastScheduleTime = &metav1.Time{Time: *mostRecentTime}
} else {
cronJob.Status.LastScheduleTime = nil
}
cronJob.Status.Active = nil
for _, activeJob := range activeJobs {
jobRef, err := ref.GetReference(r.Scheme, activeJob)
if err != nil {
log.Error(err, "unable to make reference to active job", "job", activeJob)
continue
}
cronJob.Status.Active = append(cronJob.Status.Active, *jobRef)
}
在这里,我们将记录我们在稍高的日志记录级别观察到的job数量,以便进行调试。请注意,我们没有使用格式字符串,而是使用固定消息,并将键值对与额外信息附加在一起。这样可以更轻松地筛选和查询日志行。
log.V(1).Info("job count", "active jobs", len(activeJobs), "successful jobs", len(successfulJobs), "failed jobs", len(failedJobs))
使用我们收集的日期,我们将更新 CRD 的状态。就像以前一样,我们使用我们的客户。为了专门更新状态子资源,我们将使用客户端的 Status 部分和 Update 方法。
//状态子资源忽略对规范的更改,因此它不太可能与任何其他更新冲突,并且可以具有单独的权限。
if err := r.Status().Update(ctx, &cronJob); err != nil {
log.Error(err, "unable to update CronJob status")
return ctrl.Result{}, err
}
更新状态后,我们可以继续确保世界的状态符合spec中的要求。最后,我们将尝试清理旧 job,这样我们就不会留下太多垃圾
// NB: deleting these is "best effort" -- if we fail on a particular one,
// we won't requeue just to finish the deleting.
if cronJob.Spec.FailedJobsHistoryLimit != nil {
sort.Slice(failedJobs, func(i, j int) bool {
if failedJobs[i].Status.StartTime == nil {
return failedJobs[j].Status.StartTime != nil
}
return failedJobs[i].Status.StartTime.Before(failedJobs[j].Status.StartTime)
})
for i, job := range failedJobs {
if int32(i) >= int32(len(failedJobs))-*cronJob.Spec.FailedJobsHistoryLimit {
break
}
if err := r.Delete(ctx, job, client.PropagationPolicy(metav1.DeletePropagationBackground)); client.IgnoreNotFound(err) != nil {
log.Error(err, "unable to delete old failed job", "job", job)
} else {
log.V(0).Info("deleted old failed job", "job", job)
}
}
}
if cronJob.Spec.SuccessfulJobsHistoryLimit != nil {
sort.Slice(successfulJobs, func(i, j int) bool {
if successfulJobs[i].Status.StartTime == nil {
return successfulJobs[j].Status.StartTime != nil
}
return successfulJobs[i].Status.StartTime.Before(successfulJobs[j].Status.StartTime)
})
for i, job := range successfulJobs {
if int32(i) >= int32(len(successfulJobs))-*cronJob.Spec.SuccessfulJobsHistoryLimit {
break
}
if err := r.Delete(ctx, job, client.PropagationPolicy(metav1.DeletePropagationBackground)); (err) != nil {
log.Error(err, "unable to delete old successful job", "job", job)
} else {
log.V(0).Info("deleted old successful job", "job", job)
}
}
}
4.检查我们是否暂停
如果此对象已挂起,则我们不想运行任何job,因此现在将停止。如果我们正在运行的job出现问题,并且我们希望暂停运行以调查或放置集群,而不删除对象,这将非常有用。
if cronJob.Spec.Suspend != nil && *cronJob.Spec.Suspend {
log.V(1).Info("cronjob suspended, skipping")
return ctrl.Result{}, nil
}
5.获取下一次 scheduled run
如果我们没有暂停,我们需要计算下一个计划的运行,以及我们是否有尚未处理的运行。
//getNextSchedule
// figure out the next times that we need to create
// jobs at (or anything we missed).
missedRun, nextRun, err := getNextSchedule(&cronJob, r.Now())
if err != nil {
log.Error(err, "unable to figure out CronJob schedule")
// we don't really care about requeuing until we get an update that
// fixes the schedule, so don't return an error
return ctrl.Result{}, nil
}
我们将准备最终请求以重新排队,直到下一个job,然后确定我们是否真的需要运行。
scheduledResult := ctrl.Result{RequeueAfter: nextRun.Sub(r.Now())} // save this so we can re-use it elsewhere
log = log.WithValues("now", r.Now(), "next run", nextRun)
6:如果新job按计划运行、未超过截止时间且未被我们的并发策略阻止,则运行新job
如果我们错过了一次run,并且我们仍在开始它的截止日期内,我们将需要运行一个job。
if missedRun.IsZero() {
log.V(1).Info("no upcoming scheduled times, sleeping until next")
return scheduledResult, nil
}
// make sure we're not too late to start the run
log = log.WithValues("current run", missedRun)
tooLate := false
if cronJob.Spec.StartingDeadlineSeconds != nil {
tooLate = missedRun.Add(time.Duration(*cronJob.Spec.StartingDeadlineSeconds) * time.Second).Before(r.Now())
}
if tooLate {
log.V(1).Info("missed starting deadline for last run, sleeping till next")
// TODO(directxman12): events
return scheduledResult, nil
}
如果我们实际上必须运行一个job,我们需要等到现有的job完成,替换现有的job,或者只是添加新的job。如果我们的信息由于缓存延迟而过期,我们将在获取最新信息时重新排队。
// figure out how to run this job -- concurrency policy might forbid us from running
// multiple at the same time...
if cronJob.Spec.ConcurrencyPolicy == batch.ForbidConcurrent && len(activeJobs) > 0 {
log.V(1).Info("concurrency policy blocks concurrent runs, skipping", "num active", len(activeJobs))
return scheduledResult, nil
}
// ...or instruct us to replace existing ones...
if cronJob.Spec.ConcurrencyPolicy == batch.ReplaceConcurrent {
for _, activeJob := range activeJobs {
// we don't care if the job was already deleted
if err := r.Delete(ctx, activeJob, client.PropagationPolicy(metav1.DeletePropagationBackground)); client.IgnoreNotFound(err) != nil {
log.Error(err, "unable to delete active job", "job", activeJob)
return ctrl.Result{}, err
}
}
}
一旦我们弄清楚如何处理现有 job,我们实际上就会创建我们想要的job。
7:当我们看到正在运行的job或下一次计划运行时重新排队
最后,我们将返回上面准备的结果,即我们希望在下一次运行需要时重新排队。这被视为最大截止日期 - 如果两者之间发生了其他变化,例如我们的工作开始或结束,我们被修改等,我们可能会更快地再次协调。
// we'll requeue once we see the running job, and update our status
return scheduledResult, nil
8.Setup 设置
最后,我们将更新我们的设置。为了让协调程序能够按其所有者快速查找job,我们需要一个索引。我们声明一个索引键,稍后可以将其用作伪字段名称,然后描述如何从 Job 对象中提取索引值。索引器将自动为我们处理命名空间,因此,如果job具有 CronJob 所有者,我们只需要提取所有者名称。
此外,我们将通知管理器此控制器拥有一些job,以便在job更改、删除等时自动调用基础 CronJob 上的协调。
var (
jobOwnerKey = ".metadata.controller"
apiGVStr = batch.GroupVersion.String()
)
func (r *CronJobReconciler) SetupWithManager(mgr ctrl.Manager) error {
// set up a real clock, since we're not in a test
if r.Clock == nil {
r.Clock = realClock{}
}
if err := mgr.GetFieldIndexer().IndexField(&kbatch.Job{}, jobOwnerKey, func(rawObj runtime.Object) []string {
// grab the job object, extract the owner...
job := rawObj.(*kbatch.Job)
owner := metav1.GetControllerOf(job)
if owner == nil {
return nil
}
// ...make sure it's a CronJob...
if owner.APIVersion != apiGVStr || owner.Kind != "CronJob" {
return nil
}
// ...and if so, return it
return []string{owner.Name}
}); err != nil {
return err
}
return ctrl.NewControllerManagedBy(mgr).
For(&batch.CronJob{}).
Owns(&kbatch.Job{}).
Complete(r)
}